
This publish is the second one a part of the DeepSeek collection specializing in mannequin customization with Amazon SageMaker HyperPod recipes (or recipes for brevity). In Part 1, we demonstrated the functionality and simplicity of fine-tuning DeepSeek-R1 distilled fashions the use of those recipes. On this publish, we use the recipes to fine-tune the unique DeepSeek-R1 671b parameter mannequin. We show this during the step by step implementation of those recipes the use of each SageMaker training jobs and SageMaker HyperPod.
Industry use case
After its public free up, DeepSeek-R1 mannequin, evolved by way of DeepSeek AI, confirmed spectacular effects throughout more than one analysis benchmarks. The mannequin follows the Mixture of Experts (MoE) structure and has 671 billion parameters. Historically, extensive fashions are neatly tailored for a large spectrum of generalized duties by way of the distinctive feature of being skilled at the large quantity of knowledge. The DeepSeek-R1 mannequin was once skilled on 14.8 trillion tokens. The unique R1 mannequin demonstrates sturdy few-shot or zero-shot studying features, permitting it to generalize to new duties and situations that weren’t a part of its authentic working towards.
Alternatively, many shoppers like to both fine-tune or run steady pre-training of those fashions to evolve it to their explicit trade programs or to optimize it for explicit duties. A monetary group may wish to customise the mannequin with their customized knowledge to help with their knowledge processing duties. Or a medical institution community can fine-tune it with their affected person information to behave as a clinical assistant for his or her docs. Superb-tuning too can lengthen the mannequin’s generalization skill. Consumers can fine-tune it with a corpus of textual content in explicit languages that aren’t absolutely represented within the authentic working towards knowledge. As an example, a mannequin fine-tuned with an extra trillion tokens of Hindi language will have the ability to enlarge the similar generalization features to Hindi.
The verdict on which mannequin to fine-tune will depend on the top utility in addition to the to be had dataset. In accordance with the quantity of proprietary knowledge, shoppers can make a decision to fine-tune the bigger DeepSeek-R1 mannequin as a substitute of doing it for probably the most distilled variations. As well as, the R1 fashions have their very own set of guardrails. Consumers may wish to fine-tune to replace the ones guardrails or enlarge on them.
Superb-tuning greater fashions like DeepSeek-R1 calls for cautious optimization to stability charge, deployment necessities, and function effectiveness. To succeed in optimum effects, organizations should meticulously make a selection a suitable setting, resolve the most efficient hyperparameters, and enforce environment friendly mannequin sharding methods.
Answer structure
SageMaker HyperPod recipes successfully cope with those necessities by way of offering a in moderation curated mixture of dispensed working towards tactics, optimizations, and configurations for cutting-edge (SOTA) open supply fashions. Those recipes have passed through in depth benchmarking, trying out, and validation to offer seamless integration with the SageMaker working towards and fine-tuning processes.
On this publish, we discover answers that show the right way to fine-tune the DeepSeek-R1 mannequin the use of those recipes on both SageMaker HyperPod or SageMaker working towards jobs. Your selection between those products and services depends upon your explicit necessities and personal tastes. When you require granular keep watch over over working towards infrastructure and in depth customization choices, SageMaker HyperPod is the perfect selection. SageMaker working towards jobs, however, is adapted for organizations that need an absolutely controlled enjoy for his or her working towards workflows. To be told extra information about those provider options, seek advice from Generative AI foundation model training on Amazon SageMaker.
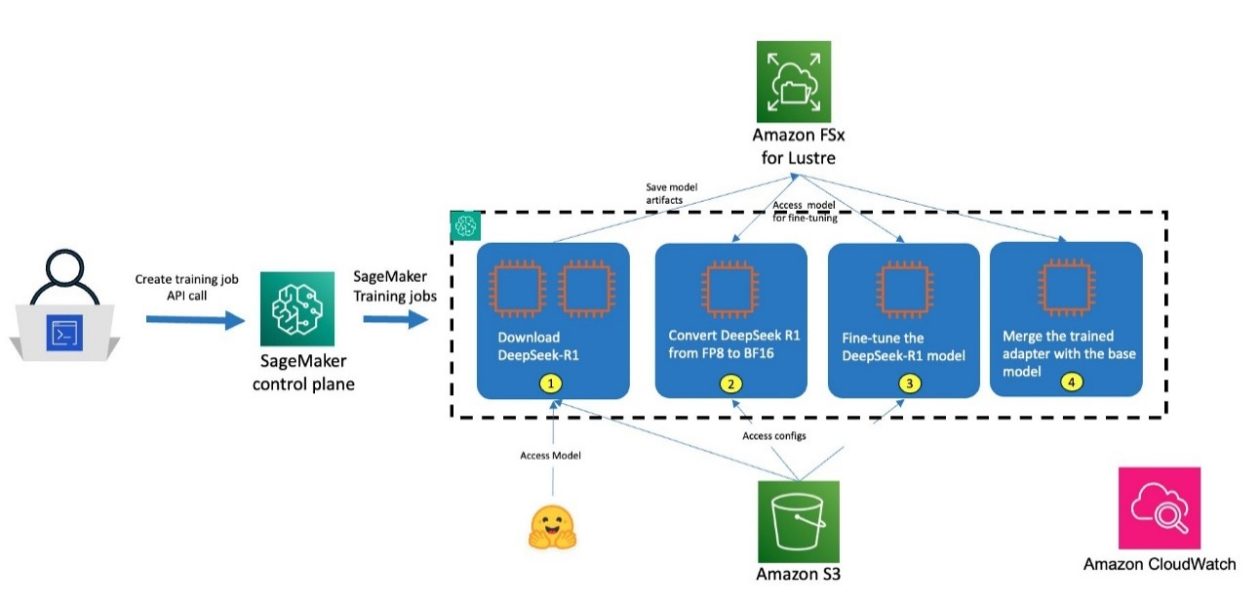
The next diagram illustrates the answer structure for working towards the use of SageMaker HyperPod. With HyperPod, customers can start the method by way of connecting to the login/head node of the Slurm cluster. Each and every step is administered as a Slurm activity and makes use of Amazon FSx for Lustre for storing mannequin checkpoints. For DeepSeek-R1, the method is composed of the next steps:
- Obtain the DeepSeek-R1 mannequin and convert weights from FP8 to BF16 structure
- Load the mannequin into reminiscence and carry out fine-tuning the use of Quantized Low-Rank Adaptation (QLoRA)
- Merge QLoRA adapters with the bottom mannequin
- Convert and cargo the mannequin for batch analysis

The next diagram illustrates the answer structure for SageMaker working towards jobs. You’ll be able to execute each and every step within the working towards pipeline by way of starting up the method during the SageMaker keep watch over aircraft the use of APIs, AWS Command Line Interface (AWS CLI), or the SageMaker ModelTrainer SDK. In reaction, SageMaker launches working towards jobs with the asked quantity and form of compute circumstances to run explicit duties. For DeepSeek-R1, the method is composed of 3 major steps:
- Obtain and convert R1 to BF16 datatype structure
- Load the mannequin into reminiscence and carry out fine-tuning
- Consolidate and cargo the checkpoints into reminiscence, then run inference and metrics to guage functionality enhancements

Necessities
Entire the next must haves earlier than working the DeepSeek-R1 671B mannequin fine-tuning pocket book:
- Make the next quota building up requests for SageMaker. You want to request no less than two
ml.p5.48xlargecircumstances (with 8 x NVIDIA H100 GPUs) ranging to a most of 4ml.p5.48xlargecircumstances (relying on time-to-train and cost-to-train trade-offs in your use case). At the Carrier Quotas console, request the next SageMaker quotas. It might probably take as much as 24 hours for the quota building up to be licensed:- P5 circumstances (
ml.p5.48xlarge) for working towards activity utilization: 2–4 - P5 circumstances (
ml.p5.48xlarge) for HyperPod clusters (ml.p5.48xlarge for cluster utilization): 2–4
- P5 circumstances (
- If you select to make use of HyperPod clusters to run your working towards, arrange a HyperPod Slurm cluster, relating to Amazon SageMaker HyperPod Developer Guide. However, you’ll additionally use the AWS CloudFormation template supplied within the Own Account workshop and observe the directions to set up a cluster and a building setting to get right of entry to and publish jobs to the cluster.
- (Not obligatory) If you select to make use of SageMaker working towards jobs, you’ll create an Amazon SageMaker Studio area (seek advice from Use quick setup for Amazon SageMaker AI) to get right of entry to Jupyter notebooks with the previous position (You’ll be able to use JupyterLab on your native setup too).
- Create an AWS Identity and Access Management (IAM) role with controlled insurance policies
AmazonSageMakerFullAccess,AmazonFSxFullAccess, andAmazonS3FullAccessto present the important get right of entry to to SageMaker to run the examples.
- Create an AWS Identity and Access Management (IAM) role with controlled insurance policies
- Clone the GitHub repository with the belongings for this deployment. This repository is composed of a pocket book that references working towards belongings:
Answer walkthrough
To accomplish the answer, observe the stairs within the subsequent sections.
Technical concerns
The default weights supplied by way of the DeepSeek staff on their reputable R1 repository are of sort FP8. Alternatively, we selected to disable FP8 in our recipes as a result of we empirically discovered that working towards with BF16 complements generalization throughout numerous datasets with minimum adjustments to the recipe hyperparameters. Due to this fact, to succeed in solid fine-tuning for a mannequin of 671b parameter measurement, we suggest first changing the mannequin from FP8 to BF16 the use of the fp8_cast_bf16.py command-line script supplied by way of DeepSeek. Executing this script will reproduction over the transformed BF16 weights in Safetensor structure to the desired output listing. Be mindful to duplicate over the mannequin’s config.yaml to the output listing so the weights are loaded appropriately. Those steps are encapsulated in a prologue script and are documented step by step underneath the Superb-tuning segment.
Consumers can use a series period of 8K for working towards, as examined on a p5.48xlarge example, each and every supplied with 8 NVIDIA H100 GPUs. You’ll be able to additionally make a choice a smaller series period if wanted. Coaching with a series period more than 8K may result in out-of-memory problems with GPUs. Additionally, changing mannequin weights from FP8 to BF16 calls for a p5.48xlarge example, which could also be really useful for working towards because of the mannequin’s excessive host reminiscence necessities all over initialization.
Consumers should improve their transformers model to transformers==4.48.2 to run the educational.
Superb-tuning
Run the finetune_deepseek_r1_671_qlora.ipynb pocket book to fine-tune the DeepSeek-R1 mannequin the use of QLoRA on SageMaker.
Get ready the dataset
This segment covers loading the FreedomIntelligence/medical-o1-reasoning-SFT dataset, tokenizing and chunking the dataset, and configuring the knowledge channels for SageMaker working towards on Amazon Simple Storage Service (Amazon S3). Entire the next steps:
- Structure the dataset by way of making use of the suggested structure for DeepSeek-R1:
- Load the FreedomIntelligence/medical-o1-reasoning-SFT dataset and cut up it into working towards and validation datasets:
- Load the DeepSeek-R1 tokenizer from the Hugging Face Transformers library and generate tokens for the practice and validation datasets. We use the unique series period of 8K:
- Get ready the educational and validation datasets for SageMaker working towards by way of saving them as
arrowrecordsdata, required by way of SageMaker HyperPod recipes, and developing the S3 paths the place those recordsdata will probably be uploaded. This dataset will probably be utilized in each SageMaker working towards jobs and SageMaker HyperPod examples:
The following segment describes the right way to run a fine-tuning instance with SageMaker working towards jobs.
Possibility A: Superb-tune the use of SageMaker working towards jobs
Practice those high-level steps:
- Obtain DeepSeek-R1 to the FSx for Lustre fastened listing
- Convert DeepSeek-R1 from FP8 to BF16
- Superb-tune the DeepSeek-R1 mannequin
- Merge the skilled adapter with the bottom mannequin
Outline a software serve as to create the ModelTrainer elegance for each step of the SageMaker working towards jobs pipeline:
Obtain DeepSeek-R1 to the FSx for Lustre fastened listing
Practice those steps:
- Make a choice the example sort, Amazon FSx knowledge channel, community configuration for the educational activity, and supply code, then outline the ModelTrainer elegance to run the educational activity at the
ml.c5.18xlargeexample to obtain DeepSeek-R1 from the Hugging Face DeepSeek-R1 hub:
- Start up the educational calling practice serve as of the ModelTrainer elegance:
Convert DeepSeek R1 from FP8 to BF16
Use ModelTrainer to transform the DeepSeek-R1 downloaded mannequin weights from FP8 to BF16 structure for optimum PEFT working towards. We use script convert.sh to run the execution the use of the ml.c5.18xlarge example.
Use SageMaker working towards heat pool configuration to retain and reuse provisioned infrastructure after the finishing touch of a mannequin obtain working towards activity within the earlier step:
Superb-tune the DeepSeek-R1 mannequin
The following segment comes to fine-tuning the DeepSeek-R1 mannequin the use of two ml.p5.48xlarge circumstances, the use of dispensed working towards. You enforce this during the SageMaker recipe hf_deepseek_r1_671b_seq8k_gpu_qlora, which comprises the QLoRA technique. QLoRA makes the large language model (LLM) trainable on restricted compute by way of quantizing the bottom mannequin to 4-bit precision whilst the use of small, trainable low-rank adapters for fine-tuning, dramatically lowering reminiscence necessities with out sacrificing mannequin high quality:
Start up the educational activity to fine-tune the mannequin. SageMaker working towards jobs will provision two P5 circumstances, orchestrate the SageMaker mannequin parallel container smdistributed-modelparallel:2.4.1-gpu-py311-cu121, and execute the recipe to fine-tune DeepSeek-R1 with the QLoRA technique on an ephemeral cluster:
Merge the skilled adapter with the bottom mannequin
Merge the skilled adapters with the bottom mannequin so it may be used for inference:
The following segment presentations how you’ll run equivalent steps on HyperPod to run your generative AI workloads.
Possibility B: Superb-tune the use of SageMaker HyperPod with Slurm
To fine-tune the mannequin the use of HyperPod, ensure that your cluster is up and able by way of following the necessities discussed previous. To get right of entry to the login/head node of the HyperPod Slurm cluster out of your building setting, observe the login directions at SSH into Cluster within the workshop.
However, you’ll additionally use AWS Systems Manager and run a command equivalent to the next to begin the consultation. You’ll be able to in finding the cluster ID, example staff call, and example ID at the Amazon SageMaker console.
- While you’re within the cluster’s login/head node, run the next instructions to arrange the surroundings. Run
sudo su - ubuntuto run the rest instructions as the basis person, until you could have a particular person ID to get right of entry to the cluster and your POSIX person is created via a lifecycle script at the cluster. Consult with the multi-user setup for extra main points.
- Create a squash dossier the use of Enroot to run the activity at the cluster. Enroot runtime gives GPU acceleration, rootless container improve, and seamless integration with HPC environments, making it superb for working workflows securely.
- After you’ve created the squash dossier, replace the
recipes_collection/config.yamldossier with absolutely the direction to the squash dossier (created within the previous step), and replace theinstance_typeif wanted. The overall config dossier must have the next parameters:
Additionally replace the dossier recipes_collection/cluster/slurm.yaml so as to add container_mounts pointing to the FSx for Lustre dossier device used on your cluster.
Practice those high-level steps to arrange, fine-tune, and assessment the mannequin the use of HyperPod recipes:
- Obtain the mannequin and convert weights to BF16
- Superb-tune the mannequin the use of QLoRA
- Merge the skilled mannequin adapter
- Review the fine-tuned mannequin
Obtain the mannequin and convert weights to BF16
Obtain the DeepSeek-R1 mannequin from the HuggingFace hub and convert the mannequin weights from FP8 to BF16. You want to transform this to make use of QLoRA for fine-tuning. Reproduction and execute the next bash script:
Superb-tune the mannequin the use of QLoRA
Obtain the ready dataset that you simply uploaded to Amazon S3 into your FSx for Lustre quantity hooked up to the cluster.
- Input the next instructions to obtain the recordsdata from Amazon S3:
- Replace the launcher script to fine-tune the DeepSeek-R1 671B mannequin. The launcher scripts function handy wrappers for executing the educational script, major.py dossier, simplifying the method of fine-tuning and parameter adjustment. For fine-tuning the DeepSeek R1 671B mannequin, you’ll in finding the precise script at:
Earlier than working the script, you want to switch the positioning of the educational and validation recordsdata, replace the HuggingFace mannequin ID, and optionally the get right of entry to token for personal fashions and datasets. The script must seem like the next (replace recipes.teacher.num_nodes for those who’re the use of a multi-node cluster):
You’ll be able to view the recipe for this fine-tuning process underneath recipes_collection/recipes/fine-tuning/deepseek/hf_deepseek_r1_671b_seq8k_gpu_qlora.yaml and override further parameters as wanted.
- Post the activity by way of working the launcher script:
Track the activity the use of Slurm instructions equivalent to squeue and scontrol display to view the standing of the activity and the corresponding logs. The logs may also be discovered within the effects folder within the release listing. When the activity is entire, the mannequin adapters are saved within the EXP_DIR that you simply outlined within the release. The construction of the listing must seem like this:
You’ll be able to see the skilled adapter weights are saved as a part of the checkpointing underneath ./checkpoints/peft_sharded/step_N. We can later use this to merge with the bottom mannequin.
Merge the skilled mannequin adapter
Practice those steps:
- Run a task the use of the
smdistributed-modelparallelenroot picture to merge the adapter with the bottom mannequin.
- Obtain the
merge_peft_checkpoint.pycode from sagemaker-hyperpod-training-adapter-for-nemo repository and retailer it in Amazon FSx. Alter the export variables within the following scripts accordingly to replicate the trails forSOURCE_DIR,ADAPTER_PATH,BASE_MODEL_BF16andMERGE_MODEL_PATH.
Review the fine-tuned mannequin
Use the elemental trying out scripts supplied by way of DeekSeek to deploy the merged mannequin.
- Get started by way of cloning their repo:
- You want to transform the merged mannequin to a particular structure for working inference. On this case, you want 4*P5 circumstances to deploy the mannequin for the reason that merged mannequin is in BF16. Input the next command to transform the mannequin:
- When the conversion is entire, use the next sbatch script to run the batch inference, making the next changes:
- Replace the
ckpt-pathto the transformed mannequin direction from the former step. - Create a brand new
activates.txtdossier with each and every line containing a suggested. The activity will use the activates from this dossier and generate output.
- Replace the
Cleanup
To wash up your sources to keep away from incurring extra fees, observe those steps:
- Delete any unused SageMaker Studio resources.
- (Not obligatory) Delete the SageMaker Studio domain.
- Examine that your working towards activity isn’t working anymore. To take action, in your SageMaker console, make a choice Coaching and take a look at Coaching jobs.
- When you created a HyperPod cluster, delete the cluster to forestall incurring prices. When you created the networking stack from the HyperPod workshop, delete the stack as neatly to wash up the digital non-public cloud (VPC) sources and the FSx for Lustre quantity.
Conclusion
On this publish, we demonstrated the right way to fine-tune extensive fashions equivalent to DeepSeek-R1 671B the use of both SageMaker working towards jobs or SageMaker HyperPod with HyperPod recipes in a couple of steps. This method minimizes the complexity of figuring out optimum dispensed working towards configurations and gives a easy strategy to correctly measurement your workloads with the most efficient price-performance structure on AWS.
To begin the use of SageMaker HyperPod recipes, discuss with our sagemaker-hyperpod-recipes GitHub repository for complete documentation and instance implementations. Our staff frequently expands our recipes in response to buyer comments and rising machine learning (ML) developments, ensuring you could have the important equipment for a success AI mannequin working towards.
Concerning the Authors
 Kanwaljit Khurmi is a Essential International Generative AI Answers Architect at AWS. He collaborates with AWS product groups, engineering departments, and shoppers to offer steering and technical help, serving to them beef up the worth in their hybrid system studying answers on AWS. Kanwaljit focuses on helping shoppers with containerized programs and high-performance computing answers.
Kanwaljit Khurmi is a Essential International Generative AI Answers Architect at AWS. He collaborates with AWS product groups, engineering departments, and shoppers to offer steering and technical help, serving to them beef up the worth in their hybrid system studying answers on AWS. Kanwaljit focuses on helping shoppers with containerized programs and high-performance computing answers.
 Arun Kumar Lokanatha is a Senior ML Answers Architect with the Amazon SageMaker staff. He focuses on extensive language mannequin working towards workloads, serving to shoppers construct LLM workloads the use of SageMaker HyperPod, SageMaker working towards jobs, and SageMaker dispensed working towards. Out of doors of labor, he enjoys working, climbing, and cooking.
Arun Kumar Lokanatha is a Senior ML Answers Architect with the Amazon SageMaker staff. He focuses on extensive language mannequin working towards workloads, serving to shoppers construct LLM workloads the use of SageMaker HyperPod, SageMaker working towards jobs, and SageMaker dispensed working towards. Out of doors of labor, he enjoys working, climbing, and cooking.
 Anoop Saha is a Sr GTM Specialist at Amazon Internet Products and services (AWS) specializing in generative AI mannequin working towards and inference. He companions with best frontier mannequin developers, strategic shoppers, and AWS provider groups to permit dispensed working towards and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and massive companies, basically specializing in silicon and device structure of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Internet Products and services (AWS) specializing in generative AI mannequin working towards and inference. He companions with best frontier mannequin developers, strategic shoppers, and AWS provider groups to permit dispensed working towards and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and massive companies, basically specializing in silicon and device structure of AI infrastructure.
 Rohith Nadimpally is a Instrument Construction Engineer operating on AWS SageMaker, the place he speeds up large-scale AI/ML workflows. Earlier than becoming a member of Amazon, he graduated with Honors from Purdue College with a point in Laptop Science. Out of doors of labor, he enjoys enjoying tennis and looking at motion pictures.
Rohith Nadimpally is a Instrument Construction Engineer operating on AWS SageMaker, the place he speeds up large-scale AI/ML workflows. Earlier than becoming a member of Amazon, he graduated with Honors from Purdue College with a point in Laptop Science. Out of doors of labor, he enjoys enjoying tennis and looking at motion pictures.
Source link