
As corporations and person customers maintain continuously rising quantities of video content material, the facility to accomplish low-effort seek to retrieve movies or video segments the usage of herbal language turns into more and more precious. Semantic video seek provides an impressive approach to this downside, so customers can seek for related video content material in response to textual queries or descriptions. This manner can be utilized in quite a lot of programs, from non-public photograph and video libraries to skilled video enhancing, or enterprise-level content material discovery and moderation, the place it will possibly considerably toughen the way in which we have interaction with and arrange video content material.
Huge-scale pre-training of laptop imaginative and prescient fashions with self-supervision without delay from herbal language descriptions of pictures has made it imaginable to seize a large set of visible ideas, whilst additionally bypassing the will for labor-intensive handbook annotation of coaching information. After pre-training, herbal language can be utilized to both reference the realized visible ideas or describe new ones, successfully enabling zero-shot switch to a various set of laptop imaginative and prescient duties, corresponding to picture classification, retrieval, and semantic research.
On this submit, we reveal use wide imaginative and prescient fashions (LVMs) for semantic video seek the usage of herbal language and picture queries. We introduce some use case-specific strategies, corresponding to temporal body smoothing and clustering, to toughen the video seek efficiency. Moreover, we reveal the end-to-end capability of this manner by way of the usage of each asynchronous and real-time web hosting choices on Amazon SageMaker AI to accomplish video, picture, and textual content processing the usage of publicly to be had LVMs at the Hugging Face Model Hub. In the end, we use Amazon OpenSearch Serverless with its vector engine for low-latency semantic video seek.
About wide imaginative and prescient fashions
On this submit, we put into effect video seek features the usage of multimodal LVMs, which combine textual and visible modalities throughout the pre-training segment, the usage of ways corresponding to contrastive multimodal illustration finding out, Transformer-based multimodal fusion, or multimodal prefix language modeling (for extra main points, see, Review of Large Vision Models and Visual Prompt Engineering by way of J. Wang et al.). Such LVMs have just lately emerged as foundational development blocks for quite a lot of laptop imaginative and prescient duties. Owing to their capacity to be informed all kinds of visible ideas from huge datasets, those fashions can successfully clear up various downstream laptop imaginative and prescient duties throughout other picture distributions with out the will for fine-tuning. On this phase, we in brief introduce one of the hottest publicly to be had LVMs (which we additionally use within the accompanying code pattern).
The CLIP (Contrastive Language-Symbol Pre-training) fashion, presented in 2021, represents an important milestone within the box of laptop imaginative and prescient. Educated on a number of 400 million image-text pairs harvested from the web, CLIP showcased the exceptional attainable of the usage of large-scale herbal language supervision for finding out wealthy visible representations. Thru intensive critiques throughout over 30 laptop imaginative and prescient benchmarks, CLIP demonstrated spectacular zero-shot switch features, regularly matching and even surpassing the efficiency of absolutely supervised, task-specific fashions. For example, a notable fulfillment of CLIP is its talent to check the highest accuracy of a ResNet-50 fashion educated at the 1.28 million photographs from the ImageNet dataset, in spite of running in a real zero-shot environment and not using a want for fine-tuning or different get admission to to classified examples.
Following the good fortune of CLIP, the open-source initiative OpenCLIP additional complicated the state of the art by way of freeing an open implementation pre-trained at the huge LAION-2B dataset, produced from 2.3 billion English image-text pairs. This considerable build up within the scale of coaching information enabled OpenCLIP to succeed in even higher zero-shot efficiency throughout quite a lot of laptop imaginative and prescient benchmarks, demonstrating additional attainable of scaling up herbal language supervision for finding out extra expressive and generalizable visible representations.
In the end, the set of SigLIP (Sigmoid Loss for Language-Symbol Pre-training) fashions, together with one educated on a ten billion multilingual image-text dataset spanning over 100 languages, additional driven the bounds of large-scale multimodal finding out. The fashions suggest an alternate loss serve as for the contrastive pre-training scheme hired in CLIP and feature proven awesome efficiency in language-image pre-training, outperforming each CLIP and OpenCLIP baselines on quite a lot of laptop imaginative and prescient duties.
Resolution evaluate
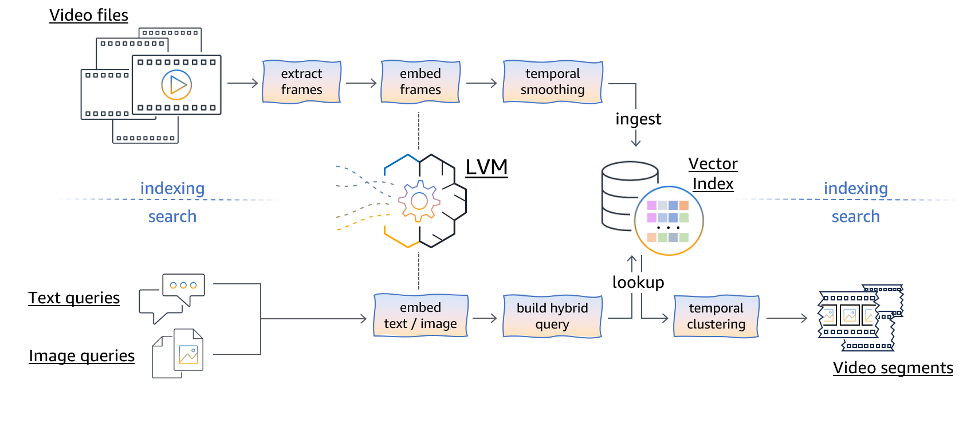
Our manner makes use of a multimodal LVM to permit environment friendly video seek and retrieval in response to each textual and visible queries. The manner can also be logically break up into an indexing pipeline, which can also be performed offline, and a web-based video seek common sense. The next diagram illustrates the pipeline workflows.

The indexing pipeline is accountable for drinking video information and preprocessing them to build a searchable index. The method starts by way of extracting person frames from the video information. Those extracted frames are then handed thru an embedding module, which makes use of the LVM to map every body right into a high-dimensional vector illustration containing its semantic data. To account for temporal dynamics and movement data provide within the video, a temporal smoothing method is carried out to the body embeddings. This step makes certain the ensuing representations seize the semantic continuity throughout more than one next video frames, somewhat than treating every body independently (additionally see the consequences mentioned later on this submit, or seek the advice of the next paper for extra main points). The temporally smoothed body embeddings are then ingested right into a vector index information construction, which is designed for environment friendly garage, retrieval, and similarity seek operations. This listed illustration of the video frames serves as the basis for the following seek pipeline.
The quest pipeline facilitates content-based video retrieval by way of accepting textual queries or visible queries (photographs) from customers. Textual queries are first embedded into the shared multimodal illustration area the usage of the LVM’s textual content encoding features. In a similar way, visible queries (photographs) are processed throughout the LVM’s visible encoding department to procure their corresponding embeddings.
After the textual or visible queries are embedded, we will construct a hybrid question to account for key phrases or filter out constraints supplied by way of the consumer (for instance, to go looking best throughout sure video classes, or to go looking inside of a specific video). This hybrid question is then used to retrieve essentially the most related body embeddings in response to their conceptual similarity to the question, whilst adhering to any supplementary key phrase constraints.
The retrieved body embeddings are then subjected to temporal clustering (additionally see the consequences later on this submit for extra main points), which targets to workforce contiguous frames into semantically coherent video segments, thereby returning a whole video collection (somewhat than disjointed person frames).
Moreover, keeping up seek range and high quality is the most important when retrieving content material from movies. As discussed prior to now, our manner accommodates quite a lot of learn how to toughen seek effects. As an example, throughout the video indexing segment, the next ways are hired to regulate the quest effects (the parameters of which would possibly wish to be tuned to get the most productive effects):
- Adjusting the sampling price, which determines the choice of frames embedded from every 2nd of video. Much less common body sampling would possibly make sense when operating with longer movies, while extra common body sampling could be had to catch fast-occurring occasions.
- Enhancing the temporal smoothing parameters to, for instance, take away inconsistent seek hits in response to only a unmarried body hit, or merge repeated body hits from the similar scene.
All the way through the semantic video seek segment, you’ll be able to use the next strategies:
- Making use of temporal clustering as a post-filtering step at the retrieved timestamps to workforce contiguous frames into semantically coherent video clips (that may be, in idea, without delay performed again by way of the end-users). This makes certain the quest effects care for temporal context and continuity, warding off disjointed person frames.
- Atmosphere the quest dimension, which can also be successfully mixed with temporal clustering. Expanding the quest dimension makes certain the related frames are integrated within the ultimate effects, albeit at the price of upper computational load (see, for instance, this guide for extra main points).
Our manner targets to strike a steadiness between retrieval high quality, range, and computational potency by way of using those ways throughout each the indexing and seek levels, in the long run improving the consumer revel in in semantic video seek.
The proposed resolution structure supplies environment friendly semantic video seek by way of the usage of open supply LVMs and AWS products and services. The structure can also be logically divided into two elements: an asynchronous video indexing pipeline and on-line content material seek common sense. The accompanying sample code on GitHub showcases construct, experiment in the neighborhood, in addition to host and invoke each portions of the workflow the usage of a number of open supply LVMs to be had at the Hugging Face Fashion Hub (CLIP, OpenCLIP, and SigLIP). The next diagram illustrates this structure.

The pipeline for asynchronous video indexing is produced from the next steps:
- The consumer uploads a video report to an Amazon Simple Storage Service (Amazon S3) bucket, which initiates the indexing procedure.
- The video is shipped to a SageMaker asynchronous endpoint for processing. The processing steps contain:
- Deciphering of frames from the uploaded video report.
- Era of body embeddings by way of LVM.
- Utility of temporal smoothing, accounting for temporal dynamics and movement data provide within the video.
- The body embeddings are ingested into an OpenSearch Serverless vector index, designed for environment friendly garage, retrieval, and similarity seek operations.
SageMaker asynchronous inference endpoints are well-suited for dealing with requests with wide payloads, prolonged processing instances, and close to real-time latency necessities. This SageMaker capacity queues incoming requests and processes them asynchronously, accommodating wide payloads and lengthy processing instances. Asynchronous inference allows price optimization by way of mechanically scaling the example depend to 0 when there aren’t any requests to procedure, so computational sources are used best when actively dealing with requests. This adaptability makes it an excellent selection for programs involving wide information volumes, corresponding to video processing, whilst keeping up responsiveness and environment friendly useful resource usage.
OpenSearch Serverless is an on-demand serverless model for Amazon OpenSearch Service. We use OpenSearch Serverless as a vector database for storing embeddings generated by way of the LVM. The index created within the OpenSearch Serverless assortment serves because the vector retailer, enabling environment friendly garage and speedy similarity-based retrieval of related video segments.
The web content material seek then can also be damaged right down to the next steps:
- The consumer supplies a textual advised or a picture (or each) representing the required content material to be searched.
- The consumer advised is shipped to a real-time SageMaker endpoint, which leads to the next movements:
- An embedding is generated for the textual content or picture question.
- The question with embeddings is shipped to the OpenSearch vector index, which plays a k-nearest neighbors (k-NN) seek to retrieve related body embeddings.
- The retrieved body embeddings go through temporal clustering.
- The overall seek effects, comprising related video segments, are returned to the consumer.
SageMaker real-time inference fits workloads wanting real-time, interactive, low-latency responses. Deploying fashions to SageMaker web hosting products and services supplies absolutely controlled inference endpoints with computerized scaling features, offering optimum efficiency for real-time necessities.
Code and setting
This submit is accompanied by way of a sample code on GitHub that gives complete annotations and code to arrange the vital AWS sources, experiment in the neighborhood with pattern video information, after which deploy and run the indexing and seek pipelines. The code pattern is designed to exemplify easiest practices when creating ML answers on SageMaker, corresponding to the usage of configuration information to outline versatile inference stack parameters and engaging in native assessments of the inference artifacts prior to deploying them to SageMaker endpoints. It additionally comprises guided implementation steps with explanations and reference for configuration parameters. Moreover, the pocket book automates the cleanup of all provisioned sources.
Must haves
The prerequisite to run the supplied code is to have an lively AWS account and arrange Amazon SageMaker Studio. Discuss with Use quick setup for Amazon SageMaker AI to arrange SageMaker when you’re a first-time consumer after which observe the stairs to open SageMaker Studio.
Deploy the answer
To start out the implementation to clone the repository, open the pocket book semantic_video_search_demo.ipynb, and observe the stairs within the pocket book.
In Segment 2 of the pocket book, set up the specified programs and dependencies, outline international variables, arrange Boto3 purchasers, and fasten required permissions to the SageMaker AWS Identity and Access Management (IAM) position to have interaction with Amazon S3 and OpenSearch Carrier from the pocket book.
In Segment 3, create safety elements for OpenSearch Serverless (encryption coverage, community coverage, and information get admission to coverage) after which create an OpenSearch Serverless assortment. For simplicity, on this evidence of thought implementation, we permit public web get admission to to the OpenSearch Serverless assortment useful resource. Then again, for manufacturing environments, we strongly counsel the usage of non-public connections between your Digital Non-public Cloud (VPC) and OpenSearch Serverless sources thru a VPC endpoint. For extra main points, see Access Amazon OpenSearch Serverless using an interface endpoint (AWS PrivateLink).
In Segment 4, import and investigate cross-check the config report, and select an embeddings fashion for video indexing and corresponding embeddings measurement. In Segment 5, create a vector index inside the OpenSearch assortment you created previous.
To reveal the quest effects, we additionally supply references to a couple of pattern movies that you’ll be able to experiment with in Segment 6. In Segment 7, you’ll be able to experiment with the proposed semantic video seek manner in the neighborhood within the pocket book, prior to deploying the inference stacks.
In Sections 8, 9, and 10, we offer code to deploy two SageMaker endpoints: an asynchronous endpoint for video embedding and indexing and a real-time inference endpoint for video seek. After those steps, we additionally check our deployed sematic video seek resolution with a couple of instance queries.
In the end, Segment 11 comprises the code to wash up the created sources to steer clear of ordinary prices.
Effects
The answer was once evaluated throughout a various vary of use circumstances, together with the identity of key moments in sports activities video games, particular outfit items or colour patterns on style runways, and different duties in full-length movies at the style business. Moreover, the answer was once examined for detecting action-packed moments like explosions in motion motion pictures, figuring out when folks entered video surveillance spaces, and extracting particular occasions corresponding to sports activities award ceremonies.
For our demonstration, we created a video catalog consisting of the next movies: A Look Back at New York Fashion Week: Men’s, F1 Insights powered by AWS, Amazon Air’s newest aircraft, the A330, is here, and Now Go Build with Werner Vogels – Autonomous Trucking.
To reveal the quest capacity for figuring out particular gadgets throughout this video catalog, we hired 4 textual content activates and 4 photographs. The introduced effects had been acquired the usage of the google/siglip-so400m-patch14-384 fashion, with temporal clustering enabled and a timestamp filter out set to one 2nd. Moreover, smoothing was once enabled with a kernel dimension of eleven, and the quest dimension was once set to twenty (which have been discovered to be excellent default values for shorter movies). The left column within the next figures specifies the quest sort, both by way of picture or textual content, at the side of the corresponding picture title or textual content advised used.
The next determine presentations the textual content activates we used and the corresponding effects.

The next determine presentations the pictures we used to accomplish opposite photographs seek and corresponding seek effects for every picture.

As discussed, we carried out temporal clustering within the search for code, taking into account the grouping of frames in response to their ordered timestamps. The accompanying notebook with sample code showcases the temporal clustering capability by way of exhibiting (a couple of frames from) the returned video clip and highlighting the important thing body with the perfect seek ranking inside of every workforce, as illustrated within the following determine. This manner facilitates a handy presentation of the quest effects, enabling customers to go back whole playable video clips (although no longer all frames had been in truth listed in a vector retailer).

To exhibit the hybrid seek features with OpenSearch Carrier, we provide effects for the textual advised “sky,” with all different seek parameters set identically to the former configurations. We reveal two distinct circumstances: an unconstrained semantic seek throughout all of the listed video catalog, and a seek confined to a particular video. The next determine illustrates the consequences acquired from an unconstrained semantic seek question.

We performed the similar seek for “sky,” however now confined to trucking movies.

For instance the results of temporal smoothing, we generated seek sign ranking charts (in response to cosine similarity) for the advised F1 crews alternate tyres within the formulaone video, each with and with out temporal smoothing. We set a threshold of 0.315 for representation functions and highlighted video segments with ratings exceeding this threshold. With out temporal smoothing (see the next determine), we seen two adjoining episodes round t=35 seconds and two further episodes after t=65 seconds. Particularly, the 3rd and fourth episodes had been considerably shorter than the primary two, in spite of showing upper ratings. Then again, we will do higher, if our function is to prioritize longer semantically cohesive video episodes within the seek.

To handle this, we practice temporal smoothing. As proven within the following determine, now the primary two episodes seem to be merged right into a unmarried, prolonged episode with the perfect ranking. The 3rd episode skilled a slight ranking aid, and the fourth episode turned into inappropriate because of its brevity. Temporal smoothing facilitated the prioritization of longer and extra coherent video moments related to the quest question by way of consolidating adjoining high-scoring segments and suppressing remoted, brief occurrences.

Blank up
To scrub up the sources created as a part of this resolution, discuss with the cleanup phase within the supplied pocket book and execute the cells on this phase. This may delete the created IAM insurance policies, OpenSearch Serverless sources, and SageMaker endpoints to steer clear of ordinary fees.
Barriers
Right through our paintings in this undertaking, we additionally recognized a number of attainable barriers which may be addressed thru long term paintings:
- Video high quality and backbone would possibly affect seek efficiency, as a result of blurred or low-resolution movies could make it difficult for the fashion to correctly determine gadgets and complex main points.
- Small gadgets inside of movies, corresponding to a hockey puck or a soccer, could be tough for LVMs to constantly acknowledge because of their diminutive dimension and visibility constraints.
- LVMs would possibly battle to understand scenes that constitute a temporally extended contextual state of affairs, corresponding to detecting a point-winning shot in tennis or a automobile overtaking some other car.
- Correct computerized size of resolution efficiency is hindered with out the provision of manually classified flooring reality information for comparability and analysis.
Abstract
On this submit, we demonstrated some great benefits of the zero-shot method to enforcing semantic video seek the usage of both textual content activates or photographs as enter. This manner readily adapts to various use circumstances with out the will for retraining or fine-tuning fashions in particular for video seek duties. Moreover, we presented ways corresponding to temporal smoothing and temporal clustering, which considerably toughen the standard and coherence of video seek effects.
The proposed structure is designed to facilitate an economical manufacturing setting with minimum effort, getting rid of the requirement for intensive experience in system finding out. Moreover, the present structure seamlessly incorporates the combination of open supply LVMs, enabling the implementation of customized preprocessing or postprocessing common sense throughout each the indexing and seek levels. This adaptability is made imaginable by way of the usage of SageMaker asynchronous and real-time deployment choices, offering an impressive and flexible resolution.
You’ll be able to put into effect semantic video seek the usage of other approaches or AWS products and services. For similar content material, discuss with the next AWS weblog posts as examples on semantic seek the usage of proprietary ML fashions: Implement serverless semantic search of image and live video with Amazon Titan Multimodal Embeddings or Build multimodal search with Amazon OpenSearch Service.
In regards to the Authors
 Dr. Alexander Arzhanov is an AI/ML Specialist Answers Architect founded in Frankfurt, Germany. He is helping AWS consumers design and deploy their ML answers around the EMEA area. Previous to becoming a member of AWS, Alexander was once researching origins of heavy components in our universe and grew captivated with ML after the usage of it in his large-scale clinical calculations.
Dr. Alexander Arzhanov is an AI/ML Specialist Answers Architect founded in Frankfurt, Germany. He is helping AWS consumers design and deploy their ML answers around the EMEA area. Previous to becoming a member of AWS, Alexander was once researching origins of heavy components in our universe and grew captivated with ML after the usage of it in his large-scale clinical calculations.
 Dr. Ivan Sosnovik is an Carried out Scientist within the AWS Gadget Studying Answers Lab. He develops ML answers to lend a hand consumers to succeed in their trade objectives.
Dr. Ivan Sosnovik is an Carried out Scientist within the AWS Gadget Studying Answers Lab. He develops ML answers to lend a hand consumers to succeed in their trade objectives.
 Nikita Bubentsov is a Cloud Gross sales Consultant founded in Munich, Germany, and a part of Technical Box Neighborhood (TFC) in laptop imaginative and prescient and system finding out. He is helping venture consumers power trade price by way of adopting cloud answers and helps AWS EMEA organizations within the laptop imaginative and prescient space. Nikita is captivated with laptop imaginative and prescient and the long run attainable that it holds.
Nikita Bubentsov is a Cloud Gross sales Consultant founded in Munich, Germany, and a part of Technical Box Neighborhood (TFC) in laptop imaginative and prescient and system finding out. He is helping venture consumers power trade price by way of adopting cloud answers and helps AWS EMEA organizations within the laptop imaginative and prescient space. Nikita is captivated with laptop imaginative and prescient and the long run attainable that it holds.
Source link